Ketika kita berbincang dengan AI seperti ChatGPT, banyak orang mengira jawabannya sekadar hasil pencarian cepat atau rumus matematis yang kaku. Padahal, ada teknologi penting di balik layar yang membuat AI mampu memahami konteks, sopan, relevan, dan terasa “manusiawi”. Salah satu teknologi kunci tersebut adalah Reinforcement Learning from Human Feedback (RLHF).
RLHF menjadi fondasi utama dalam pengembangan AI modern, terutama Large Language Model (LLM). Tanpa RLHF, AI mungkin masih pintar secara teknis, tetapi canggung, tidak sensitif konteks, dan berpotensi menghasilkan jawaban berbahaya. Artikel ini akan mengupas RLHF secara menyeluruh, mulai dari konsep dasar hingga dampaknya dalam kehidupan sehari-hari.
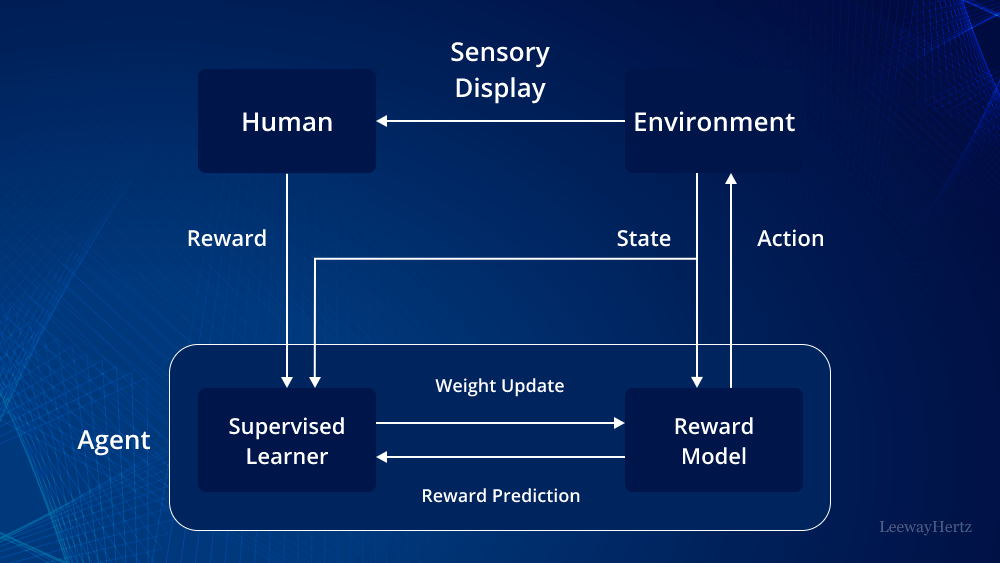
1. Apa Itu Reinforcement Learning from Human Feedback?
Reinforcement Learning from Human Feedback atau RLHF adalah metode pelatihan kecerdasan buatan yang menggabungkan pembelajaran penguatan (reinforcement learning) dengan umpan balik manusia. Dalam pendekatan ini, manusia berperan langsung dalam membimbing AI tentang mana perilaku yang dianggap baik, buruk, tepat, atau tidak pantas.
Berbeda dengan machine learning tradisional yang hanya mengandalkan data mentah, RLHF memasukkan penilaian manusia sebagai “kompas moral dan kontekstual”. AI tidak hanya belajar dari pola teks, tetapi juga dari preferensi manusia terhadap jawaban tertentu.
Dengan RLHF, AI dilatih untuk memahami bahwa jawaban yang benar secara teknis belum tentu jawaban yang tepat secara sosial, etika, atau komunikasi. Inilah yang membuat AI modern terasa lebih halus dan adaptif.
2. Mengapa RLHF Dibutuhkan dalam Pengembangan AI?
Tanpa RLHF, AI cenderung menghasilkan jawaban yang terlalu literal, dingin, atau bahkan menyesatkan. Model bahasa besar memang dapat memprediksi kata berikutnya dengan akurat, tetapi tidak otomatis memahami nilai, empati, dan konteks manusia.
RLHF dibutuhkan karena dunia nyata penuh dengan ambiguitas. Pertanyaan manusia sering mengandung emosi, maksud tersembunyi, dan norma sosial. AI perlu belajar bahwa jawaban “paling logis” tidak selalu “paling tepat”.
Selain itu, RLHF berfungsi sebagai lapisan keamanan. Dengan umpan balik manusia, AI dilatih untuk menghindari konten berbahaya, ujaran kebencian, manipulasi, dan instruksi yang berisiko. Ini menjadikan RLHF sebagai pilar penting dalam AI yang bertanggung jawab.
Baca juga : Apa Itu Resolusi Kamera 4K? Ini Penjelasan Sederhana yang Banyak Orang Salah Paham
3. Perbedaan RLHF dengan Reinforcement Learning Biasa
Reinforcement learning klasik bekerja dengan sistem reward dan punishment berbasis aturan matematis. Contohnya, AI diberi poin jika menang dalam permainan atau mencapai target tertentu. Sistem ini efektif untuk lingkungan tertutup seperti game atau simulasi.
RLHF berbeda karena reward-nya tidak sepenuhnya berasal dari sistem otomatis, melainkan dari penilaian manusia. Manusia menilai hasil keluaran AI dan menentukan mana yang lebih baik atau lebih sesuai.
Perbedaan ini membuat RLHF jauh lebih fleksibel. AI tidak hanya mengejar skor numerik, tetapi belajar mengikuti preferensi manusia yang kompleks dan berubah-ubah. Inilah yang memungkinkan AI memahami nuansa bahasa, sopan santun, dan konteks budaya.
4. Tahapan Proses RLHF Secara Sederhana
Proses RLHF umumnya dimulai dengan pelatihan model dasar menggunakan data teks dalam jumlah besar. Pada tahap ini, AI belajar struktur bahasa, tata kalimat, dan hubungan kata.
Tahap berikutnya adalah pengumpulan umpan balik manusia. Para pelatih manusia diminta membandingkan beberapa jawaban AI untuk satu pertanyaan, lalu memilih mana yang paling baik. Data ini digunakan untuk membangun reward model.
Setelah itu, AI dilatih ulang menggunakan reinforcement learning dengan reward model tersebut. Model akan cenderung menghasilkan jawaban yang dinilai lebih baik oleh manusia, dan menghindari pola jawaban yang sebelumnya mendapat penilaian buruk.
5. Peran Manusia dalam RLHF
Manusia memiliki peran yang sangat krusial dalam RLHF. Mereka bukan sekadar pengawas, tetapi “guru” yang membentuk kepribadian dan perilaku AI. Penilaian manusia mencakup aspek akurasi, kejelasan, sopan santun, hingga etika.
Para pelatih ini biasanya mengikuti panduan ketat agar penilaian tetap konsisten. Mereka dilatih untuk mengenali bias, potensi bahaya, dan konteks sensitif. Tanpa manusia, AI tidak memiliki standar nilai yang jelas.
Namun, keterlibatan manusia juga membawa tantangan. Preferensi manusia bisa berbeda-beda, sehingga RLHF harus dirancang untuk menyeimbangkan berbagai sudut pandang agar AI tidak condong ke satu bias tertentu.
6. RLHF dalam ChatGPT dan Model Bahasa Modern
ChatGPT adalah salah satu contoh paling nyata penerapan RLHF. Model dasarnya sudah sangat kuat dalam memahami bahasa, tetapi RLHF membuatnya lebih sopan, relevan, dan aman digunakan oleh publik.
Melalui RLHF, ChatGPT belajar menolak permintaan berbahaya, memberikan jawaban yang lebih terstruktur, dan menyesuaikan nada bicara sesuai konteks. AI tidak hanya “menjawab”, tetapi berinteraksi.
Tanpa RLHF, ChatGPT mungkin masih pintar, tetapi akan terasa seperti mesin pencari yang berbicara panjang lebar tanpa empati atau batasan etis.
7. Dampak RLHF terhadap Keamanan dan Etika AI
RLHF memainkan peran penting dalam menjaga keamanan AI. Dengan umpan balik manusia, AI diajarkan untuk mengenali topik sensitif dan meresponsnya dengan hati-hati.
Pendekatan ini membantu mencegah penyebaran misinformasi, konten berbahaya, dan instruksi ilegal. RLHF juga memungkinkan AI menolak permintaan tertentu dengan cara yang sopan dan edukatif.
Secara etika, RLHF membantu menjembatani kesenjangan antara kecerdasan teknis dan nilai kemanusiaan. AI tidak hanya menjadi alat pintar, tetapi sistem yang lebih selaras dengan norma sosial.
8. Kelebihan RLHF Dibanding Pendekatan Lain
Salah satu keunggulan RLHF adalah fleksibilitasnya. AI dapat beradaptasi dengan preferensi pengguna dan perubahan norma sosial seiring waktu.
RLHF juga meningkatkan kualitas pengalaman pengguna. Jawaban terasa lebih alami, tidak kaku, dan lebih mudah dipahami. Hal ini sangat penting untuk aplikasi pendidikan, layanan pelanggan, dan asisten virtual.
Selain itu, RLHF memungkinkan kontrol yang lebih baik terhadap perilaku AI tanpa harus menulis aturan teknis yang rumit untuk setiap skenario.
9. Tantangan dan Keterbatasan RLHF
Meski powerful, RLHF bukan tanpa kelemahan. Proses ini mahal dan memakan waktu karena membutuhkan banyak tenaga manusia terlatih.
Selain itu, umpan balik manusia bisa mengandung bias budaya, bahasa, atau perspektif tertentu. Jika tidak dikelola dengan baik, bias ini bisa ikut “tertanam” dalam AI.
Skalabilitas juga menjadi tantangan. Semakin kompleks AI, semakin sulit menyediakan umpan balik manusia untuk semua kemungkinan interaksi.
10. Masa Depan RLHF dalam Dunia AI
Ke depan, RLHF diprediksi akan semakin berkembang dan dikombinasikan dengan metode otomatis yang lebih efisien. Tujuannya adalah mempertahankan kualitas interaksi tanpa ketergantungan penuh pada tenaga manusia.
RLHF juga akan memainkan peran besar dalam AI personal, di mana model menyesuaikan perilakunya berdasarkan preferensi individu pengguna, bukan hanya standar umum.
Pada akhirnya, RLHF adalah langkah penting menuju AI yang bukan hanya cerdas, tetapi juga bijaksana. Teknologi ini menandai pergeseran besar dari AI yang sekadar menghitung, menjadi AI yang memahami manusia.
Kesimpulan
Reinforcement Learning from Human Feedback adalah jantung dari AI modern yang ramah pengguna. Ia menjembatani kecerdasan mesin dengan nilai-nilai manusia, membuat AI lebih aman, relevan, dan bermakna.
Tanpa RLHF, AI mungkin tetap pintar, tetapi akan kehilangan sentuhan kemanusiaan. Dengan RLHF, kita tidak hanya menciptakan mesin yang bisa berpikir, tetapi sistem yang mampu berkomunikasi dan berinteraksi secara bertanggung jawab di dunia nyata.