Arsitektur Mixture of Experts (MoE): Cara AI Modern Jadi Lebih Cepat Tanpa Harus Selalu “Kerja Keras”
Dalam beberapa tahun terakhir, perkembangan model AI melonjak drastis, terutama pada model berbasis transformer dengan jumlah parameter yang mencapai ratusan miliar hingga triliunan. Masalahnya, semakin besar model, semakin mahal biaya komputasi—baik saat training maupun inferensi. Di sinilah arsitektur Mixture of Experts (MoE) muncul sebagai solusi cerdas. Alih-alih mengaktifkan seluruh jaringan saraf seperti model tradisional, MoE hanya “menyalakan” sebagian kecil dari model untuk setiap input. Hasilnya? Performa tetap tinggi, tapi jauh lebih efisien.
Berikut ini adalah pembahasan lengkap dalam format listicle yang padat, teknis, dan tetap mudah dipahami.
1. Apa Itu Mixture of Experts (MoE) dan Kenapa Jadi Revolusi?
Mixture of Experts adalah pendekatan dalam machine learning yang membagi satu model besar menjadi banyak sub-model kecil yang disebut “expert”. Setiap expert memiliki spesialisasi tertentu, dan tidak semua expert akan aktif secara bersamaan.
Berbeda dengan model dense (padat) yang memproses semua input dengan seluruh parameter, MoE hanya menggunakan sebagian kecil parameter untuk setiap token. Ini berarti model bisa memiliki kapasitas besar tanpa harus membayar biaya komputasi penuh setiap saat.
Konsep ini sebenarnya bukan hal baru, tapi implementasinya di model transformer modern membuatnya sangat relevan. Dengan MoE, model bisa diskalakan ke ukuran ekstrem tanpa bottleneck performa yang biasanya muncul pada arsitektur tradisional.
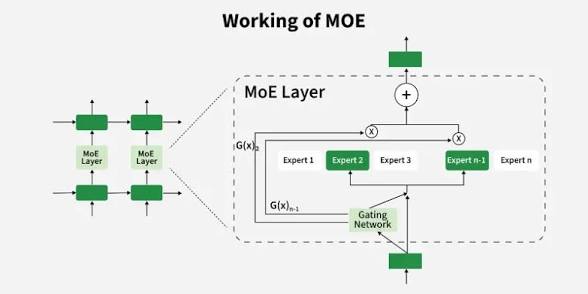
2. Komponen Utama: Expert Networks (Pakar)
Bagian pertama dari MoE adalah expert networks. Ini adalah kumpulan sub-jaringan saraf, biasanya berupa feed-forward neural networks (FFN), yang masing-masing dilatih untuk menangani jenis pola tertentu.
Setiap expert bisa dianggap seperti “spesialis”. Ada yang lebih jago menangani bahasa natural, ada yang lebih optimal untuk logika, bahkan ada yang lebih cocok untuk pola numerik atau coding.
Menariknya, semua expert ini dilatih secara bersamaan dalam satu sistem. Mereka tidak berdiri sendiri, melainkan menjadi bagian dari ekosistem yang saling melengkapi. Dalam praktiknya, jumlah expert bisa sangat banyak—mulai dari puluhan hingga ratusan dalam satu layer.
Baca juga : Extension, Plugin, dan Add-on Tidaklah Sama, Ini Perbedaannya
3. Komponen Kunci: Gating Network (Router)
Kalau expert adalah “pekerja”, maka gating network adalah “manajer” yang menentukan siapa yang harus bekerja.
Gating network bertugas menganalisis input dan menentukan expert mana yang paling relevan. Ia menghasilkan skor probabilitas untuk setiap expert, lalu memilih beberapa dengan nilai tertinggi.
Fungsi ini sangat krusial karena menentukan efisiensi dan kualitas output. Jika routing salah, maka expert yang dipilih tidak optimal dan hasilnya bisa menurun. Oleh karena itu, training gating network menjadi salah satu tantangan terbesar dalam MoE.
4. Mekanisme Routing: Bagaimana Input Dipilihkan “Ahlinya”
Saat sebuah token masuk ke layer MoE, proses pertama yang terjadi adalah routing. Gating network akan membaca representasi token tersebut dan menghitung distribusi probabilitas ke semua expert.
Dari sini, sistem akan memilih Top-K expert—biasanya 1 atau 2 expert dengan skor tertinggi. Hanya expert inilah yang akan aktif dan memproses token tersebut.
Pendekatan ini disebut sparse activation, karena hanya sebagian kecil jaringan yang digunakan. Inilah kunci efisiensi MoE dibanding model dense yang selalu mengaktifkan semua neuron.
5. Aktivasi Sparse: Kenapa Lebih Hemat dan Cepat
Dalam model tradisional, setiap layer akan memproses semua input menggunakan seluruh parameter. Ini membuat komputasi menjadi berat, terutama saat model sudah sangat besar.
MoE mengubah paradigma ini dengan hanya mengaktifkan sebagian kecil parameter. Misalnya, dalam model dengan 8 expert, hanya 2 yang aktif untuk setiap token. Artinya, hanya 25% dari kapasitas layer yang digunakan dalam satu waktu.
Efeknya sangat signifikan. Model tetap memiliki kapasitas besar (karena total parameter tetap banyak), tapi biaya komputasi per token jauh lebih rendah.
6. Output Aggregation: Menggabungkan Hasil dari Para Pakar
Setelah expert terpilih memproses input, hasilnya tidak langsung digunakan begitu saja. Output dari masing-masing expert akan digabungkan menggunakan weighted sum berdasarkan skor dari gating network.
Artinya, kontribusi setiap expert tidak selalu sama. Expert dengan skor lebih tinggi akan memberikan pengaruh lebih besar pada output akhir.
Proses ini memastikan bahwa meskipun hanya beberapa expert yang aktif, hasilnya tetap representatif dan optimal.
7. Keunggulan Utama: Skalabilitas Tanpa Batas
Salah satu kelebihan terbesar MoE adalah skalabilitas. Dalam model dense, menambah parameter berarti menambah beban komputasi secara linear. Namun di MoE, jumlah parameter bisa ditambah tanpa meningkatkan biaya inferensi secara signifikan.
Ini memungkinkan model mencapai skala sangat besar, bahkan triliunan parameter, tanpa membuat proses menjadi lambat.
Dengan kata lain, MoE memungkinkan “model besar dengan biaya kecil”—sesuatu yang sebelumnya sulit dicapai.
8. Spesialisasi: Setiap Expert Punya Keahlian Sendiri
Karena setiap expert dilatih untuk menangani subset data tertentu, mereka secara alami mengembangkan spesialisasi.
Misalnya, dalam model bahasa, beberapa expert bisa lebih fokus pada grammar, sementara yang lain lebih kuat di reasoning atau coding. Ini membuat model secara keseluruhan lebih fleksibel dan adaptif.
Pendekatan ini mirip dengan tim manusia: daripada satu orang mengerjakan semuanya, lebih efektif jika setiap orang fokus pada keahliannya masing-masing.
9. Tantangan: Load Balancing dan Routing Bias
Meski terdengar ideal, MoE juga punya tantangan besar. Salah satunya adalah load balancing. Jika gating network terlalu sering memilih expert tertentu, maka expert lain menjadi jarang digunakan.
Hal ini bisa menyebabkan ketidakseimbangan training dan membuat beberapa expert tidak berkembang optimal.
Untuk mengatasi ini, digunakan teknik regularisasi seperti auxiliary loss yang mendorong distribusi penggunaan expert lebih merata.
10. Contoh Nyata: Mixtral dan Model Besar Modern
Salah satu implementasi populer MoE adalah Mixtral 8x7B. Model ini memiliki 8 expert, tetapi hanya mengaktifkan 2 untuk setiap token. Hasilnya, performanya mendekati model besar, tapi dengan biaya komputasi yang jauh lebih rendah.
Beberapa laporan juga menyebut bahwa model seperti GPT-4 menggunakan pendekatan serupa, meskipun detailnya tidak sepenuhnya dipublikasikan.
Ini menunjukkan bahwa MoE bukan sekadar teori, melainkan sudah menjadi bagian penting dari arsitektur AI modern.
11. Integrasi dengan Transformer: Di Mana MoE Ditempatkan?
Dalam arsitektur transformer, MoE biasanya diterapkan pada bagian feed-forward layer (FFN). Layer ini adalah salah satu komponen paling “berat” dalam transformer.
Dengan mengganti FFN dense menjadi MoE, beban komputasi bisa dikurangi drastis tanpa mengorbankan performa.
Pendekatan ini memungkinkan transformer tetap efisien meskipun skalanya terus diperbesar.
12. Masa Depan MoE: Menuju AI yang Lebih Cerdas dan Efisien
MoE membuka jalan menuju model AI yang tidak hanya besar, tetapi juga cerdas dalam menggunakan sumber daya. Dengan pendekatan ini, kita tidak lagi terjebak pada dilema antara performa dan efisiensi.
Ke depan, MoE kemungkinan akan dikombinasikan dengan teknik lain seperti quantization, distillation, dan edge inference untuk menciptakan AI yang lebih ringan namun tetap powerful.
Kesimpulan: MoE Adalah “Otak Modular” untuk AI Modern
Mixture of Experts mengubah cara kita memandang arsitektur AI. Dari sistem monolitik yang berat, menjadi sistem modular yang fleksibel dan efisien.
Dengan hanya mengaktifkan sebagian kecil jaringan untuk setiap input, MoE mampu menghadirkan performa tinggi dengan biaya rendah. Ditambah lagi dengan kemampuan spesialisasi dan skalabilitas yang luar biasa, MoE menjadi fondasi penting bagi generasi AI berikutnya.
Jika model dense adalah “otak besar yang bekerja terus-menerus”, maka MoE adalah “tim ahli” yang hanya bekerja saat dibutuhkan—lebih cerdas, lebih hemat, dan jauh lebih efisien.